关于 Ray 的一些笔记和想法。
背景
2018 年开源的 Ray,从创始之初就被不少科技媒体所吹捧是 Spark 在未来的替代品。然而在 Ray 的 paper 中,明确指出了 Ray 是针对 Reinforcement Learning 的需求而设计。其中开头这样写道,在监督式机器学习中,数据在离线环境中经过训练,再部署到线上环境,中间需要经过一个冗长的处理流程,使得数据的赋能业务的周期通常为小时或者天级别。而这样的方式,在一些新兴行业如自动驾驶上,显然是不满足要求的。
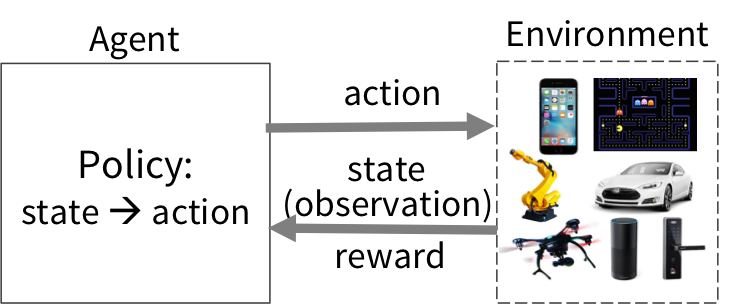
针对这个 RL 系统,我们将优化 Policy 的代码抽象如下:
def rollout(policy, environment):
state <- environment.initial_state()
// 不断迭代直到模拟失败
while (not environment.has_terminated):
action <- policy.compute(state)
state,reward <- environment.step(action)
trajectory.append(state, reward)
return trajectory
def train_policy(environment):
policy <- initial_policy()
while (policy not converged):
// 对于每个 policy 进行 k 次模拟实验
for i from 1 to k:
trajectory.append(rollout(policy, environment))
policy := policy.update(trajectories)
return policy
增强学习和传统的监督式机器学习区别如下:
- 最终效果很大程度上依赖于模拟环境下的大量试错,大量反馈,task 的数量很多,运算量很大
- 计算 DAG 可能会不断演进,每一次的模拟结果可能会决定下一次的计算拓扑
- 在面对不确定的环境变化时对实时性要求极高(毫秒级别完成百万 Tasks 的计算)
而现有的流行的计算框架 MapReduce / Spark / Tensorflow 等,都无法完全满足上述的诉求。
设计目标
Ray 的设计目标体现在以下几个方面:
- 灵活性
- Task 的异构性
- 每个并行 Task 执行不同的计算
- 每个 Task 执行的时间可能不同,比如并行的多次试验,有的试验时间持续时间长,有的试验持续时间段,每个 Task 的一些特性是不一样的,这样需要我们更灵活的对 Task 进行控制,比如及时地释放资源
- 每个 Task 的资源使用不同
- 动态拓扑,主要是和 Spark / Flink 这些先写好 Job,编译成 Graph 再运行的模式作区分,或者说 Ray 的拓扑是在 runtime 时动态形成,而不是事先编译好的
- Task 的异构性
- 高性能
- 开发友好性
- 数据回放
- 容错
- 算法并行化
架构
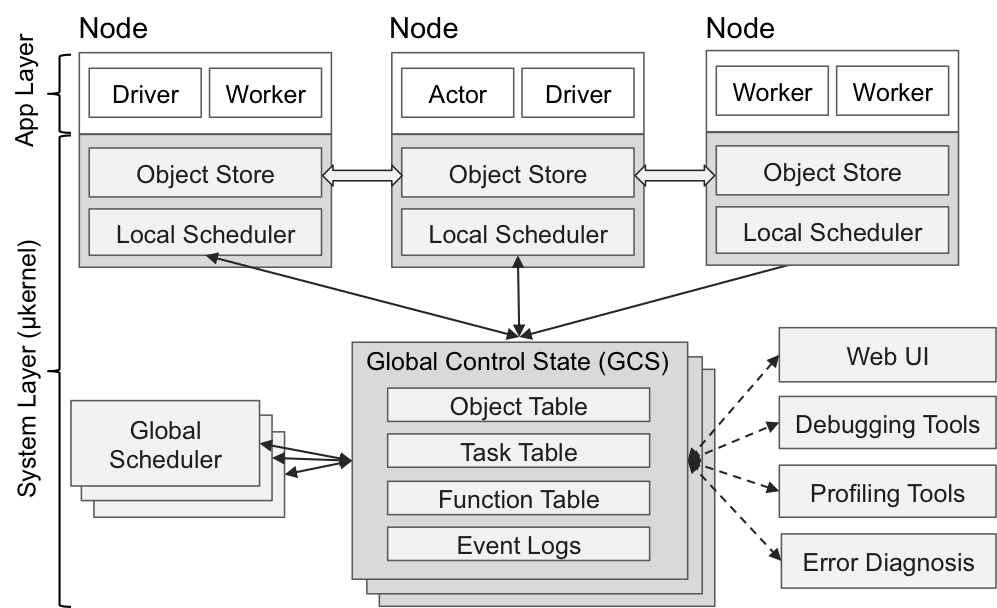
Application Layer
- Driver: 用户运行的进程
- Worker: 无状态的进程,可以执行无状态的 Task,类似 Flink 里的 TaskManager 和 Spark 里的 executor
- Actor: 有状态的进程,可以执行有状态的 Task,是由 Worker 启动的一个进程
System Layer
Bottom-Up Distributed Scheduler
每个 Node 里有一个 Local Scheduler,同时全局有一个 Global Scheduler。Task 进行 Bottom-Up 的调度,先提交给本地的 Local Scheduler,如果无法调度再通过 Global Scheduler 进行协调。Global Scheduler 可以进行横向拓展。Scheduler 的调度流程如下所示:
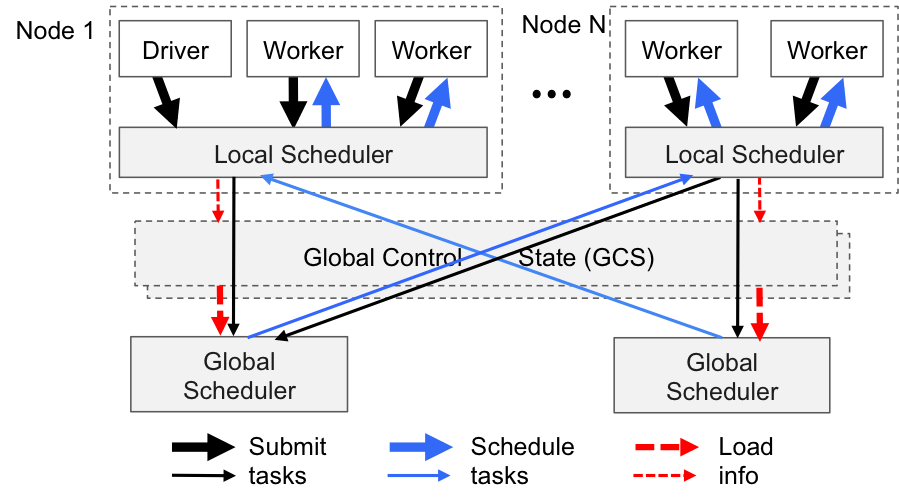
In-Memory Distributed Object Store(plasma)
状态存储,在每个节点都会有一个基于内存的 Object Store,通过 shared-memory 的方式在同一个 Node 的不同进程之间实现 zero-copy data sharing。如果一个 Task 在本地的 Object Store 中没有数据,则会从另一个节点复制过来。如果 Obejct Store 中数据丢失或者节点宕机,可以通过 graph 的血缘关系进行重新构建。
Global Control Store (GCS)
元数据管理的 Server,可以横向扩容
- Object Table:存储了 Object Store 中的 object 对应的节点位置
- Task Table: Task 执行的相关信息
- Function Table: 用户编程的 Function 或者 computation graph 之类的信息
上述三个组件串起来就是下面的图:
程序示例
以一个 a+b 的典型例子来描述这个架构是如何工作的,
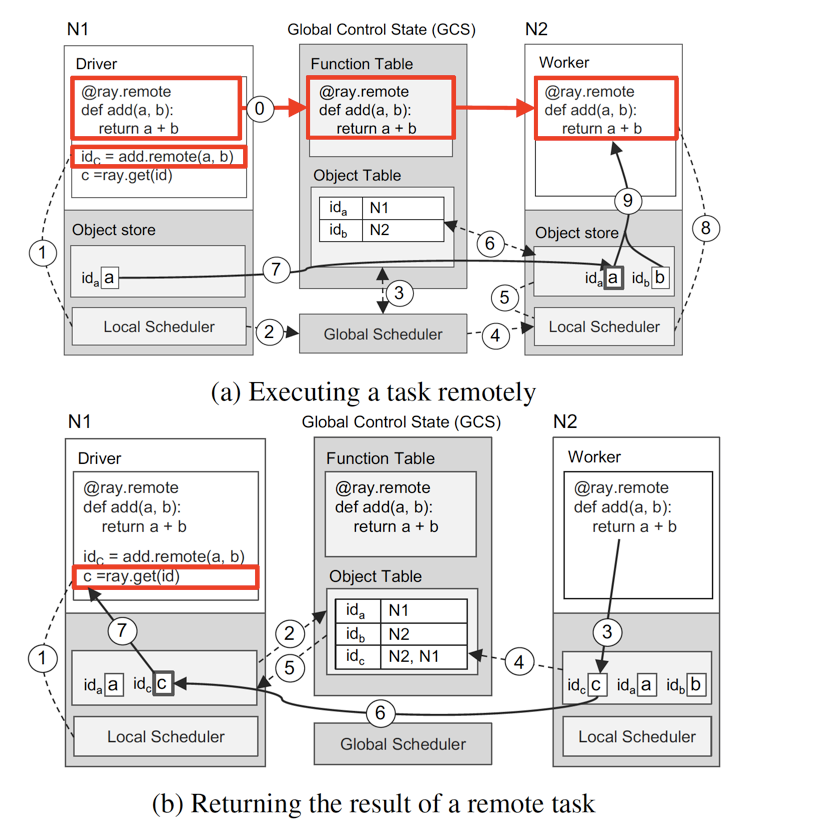
(a)
- 定义 add 函数,广播到其他节点 N2
- N1 执行 id = add.remote(a,b) 函数,先往 Local Scheduler 进行调度
- Local Scheduler 发现 N1 只有 a,没有 b,向 Global Scheduler 求助
- Global Scheduler 查询 GCS 中的 Object Table 获取 b 的位置是 N2
- Global Scheduler 调度 b 所在节点 N2 的 Local Scheduler
- b 所在节点的 Local Scheduler 发现 N2 没有 a
- b 所在节点向 GCS 中的 Object Table 查询 a 的位置是 N1
- 从 N1 的 Object Store 中拷贝 a 到本地的 Object Store
- N2 节点执行函数 a+b
(b)
b 图相对简单,不作阐述。
Programming & Computation Model
Programming Model 也是在 Paper 中多次提到的一个点,主要有如下特点:
- 相比于传统的计算引擎按 Stage 来分隔 Graph 的形式,Ray 中可以使用 ray.wait() 来根据已经收到的结果(可能是一个 subset)来决定下一步的操作。
- 资源异构,见如下例子
- Nested remote function: 可以在 remote function 中继续调用其他 remote function
- Actor: 有状态的算子
这里比较有意思的 Nested Remote Function,即可以在分布式任务的 task 中去启动一个分布式任务,这在 Spark 里,就像是在 rdd 中的 task 里调用 rdd 一样,之前有遇到过这样的应用场景,可惜 Spark 由于是支持静态拓扑的任务,所以不支持这种灵活的操作。
结论
总体看下来,Ray 在整个设计中并没有强调批和流的概念,相对提供的还是 Low-Level 的一种分布式能力。对于上层的一些机制,并没有去实现,比如我们常见的 shuffle 机制,使用 Ray 的用户可能就需要自己用 Ray 的 API 手码一个 Shuffle 逻辑出来,所以,Ray 的未来如果需要继续发扬光大的,上层的一些机制的封装必不可少。
Ray 的设计整体看下来还是有不少亮点:
- 所有中心化组件都可以横向拓展,比如 Global Scheduler 可以横向拓展,GCS 中的数据可以通过 Shard 的方式进行横向拓展,在设计初期就多方位的考虑了未来的拓展能力,这个很值得每个程序设计的人借鉴。
- Bottom-Up Distributed Scheduler,自底向上的调度器,很有想法,确实很大地加快了 Task 的调度速度,增强了整个集群的调度的吞吐能力。
- In-Memory Object Store: 其实这在 Flink 里有点像 StateBackend,但 StateBackend 由于是封装了 RocksDB 或者其他已有存储,Flink 应用层面上对这种状态的把控能力总是有些捉襟见肘,比如生产环境经常遇到底层存储的性能问题,还要经过无数次的调优也不见得有很明显的效果。Ray 在初期就采取了自研 Object Store 的方式,很明显是看到了 Object Store 在整个计算中起了一个非常核心的作用,这种做法也显得非常有前瞻性。
- Nested Remote Function 和 FaaS 式编程: 这也是动态 Graph 让 Ray 有了这种灵活的调用,目前 Flink / Spark 对于用户来说,编程显得太过麻烦和死板,这样的编程方式相信在未来一定是一个主流趋势。