一次Spark故障排查。
Spark Executor OOM: GC overhead limit exceeded
这个任务的处理过程很简单,从Kafka接收数据,经过打标签的Operator,最后写入Hive。Executor的Memory设置为2G,Spark的UnifiedMemory在1G左右,任务中用闭包传递了标签规则表,大概在350M左右(这里
应该使用广播,但是由于我们的ETL框架中有一个广播机制,不能适用,所以直接使用了闭包传递)。
首先因为这个任务确实比较轻,所以给的内存比较小,而且会存在一个非常特别的情况,当数据量特别特别大的时候,反而GC时间正常,数据量小的时候,GC时间过大导致了OOM。这就让我非常的不解,为了分析内
存使用情况,先给executor加上dump的参数,然后看看,到底是什么让垃圾收集器忙的停不下来。
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path
用JVM打开之后是这个结果:
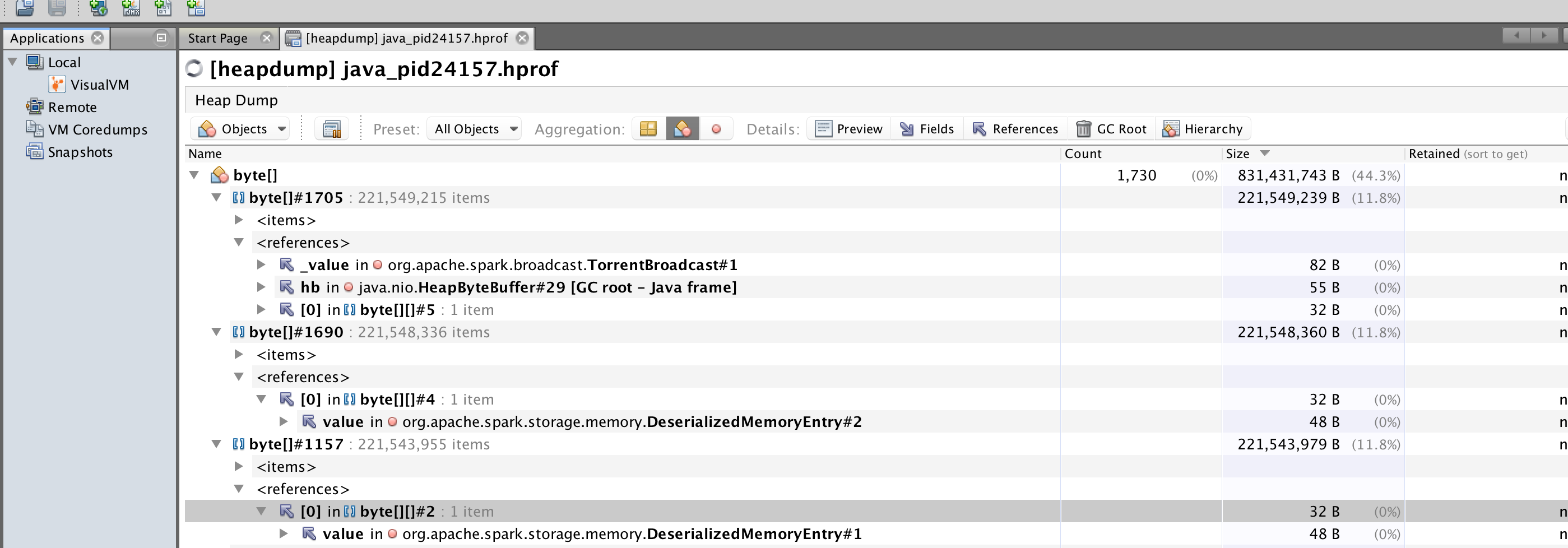
三个大的byte数组,大小还差不多,其中一个的reference是TorrentBroadcast,意料之中。另外两个没有refer到任何一个实体对象,只是以Spark内存模型中的DeserializedMemoryEntry形式而存在,因为程序很>轻,并不需要申请过多的内存,所以这样的现象实在是奇怪。没有思路,为了观察更细致的GC过程,加入了GC参数:
-XX:+PrintGCdetails
接下来可以看到一连串的GC日志(在家写博客懒得连VPN拿真实日志了):
[Full GC (Metadata GC Threshold) ...
[Full GC (Ergonomics) ...
先顺便通过调参增大了MetaspaceSize,避免了Metadata GC Threshold导致的Full GC。然后开始关注Ergonomics导致的Full GC,官方文档上这样写道:
Ergonomics is the process by which the Java Virtual Machine (JVM) and garbage collection tuning, such as behavior-based tuning, improve application performance.
Example:
UseAdaptiveSizePolicy actions to meet *** throughput goal ***
GC overhead (%)
Young generation: 16.10 (attempted to grow)
Tenured generation: 4.67 (attempted to grow)
Tenuring threshold: (attempted to decrease to balance GC costs) = 1
意思就是根据历史的内存情况,如果与JVM所要求的目标相差太远,就实时的动态修改JVM的相关参数,如上所示,为了达到throughput goad,需要balance新生代和老年代的GC overhead时间,于是降低Tenuring threshold,使得新生代对象,更容易进入Tenured Generation。
在观察若干次后,发现大对象多次进入老年代,导致了频繁的Full GC,也就是之前dump日志中的那两个不知哪儿来的byte数组。此时联想到了之前,大数据量时GC overhead没问题,小数据量GC overhead过大的情
况,才明白由于闭包传递规则表,导致每次部署新的task时,都要往老年代放一个task binary的大对象,而在数据量较小时,任务结束较快,甚至快过了GC的时间,导致Executor连续处理小任务时不断进行Full GC,然后造成OOM。