之前总是听到别人说 Flink 本身的反压机制有多么优秀,直到自己真正在应用中碰巧踩到坑,仔细研究后才发现,这个反压机制貌似并不完美。
Network Stack
关于 Apache Flink 本身的网络栈研究,不少人都写过博客叙述:
熟悉网络栈之后,我们知道,在 RemoteChannel 的接收数据部分,提供了 m+n 即 Floating Buffer + Exclusive Buffer 的接收数据空间,由于每个 RemoteInputChannel 都有自己独立的 Exclusive Buffer,所以同一个 Taskmanager 的不同 RemoteInputChannel 在接收数据时不会互相阻塞。
从接收端看,确实没有什么问题,好像确实消费慢的 InputChannel 没有阻塞到消费快的 InputChannel。然而,从发送端看,就不是这样了,我画了一个示意图,为了方便,在示意图中就没有画出接收端的 credit-based 机制:
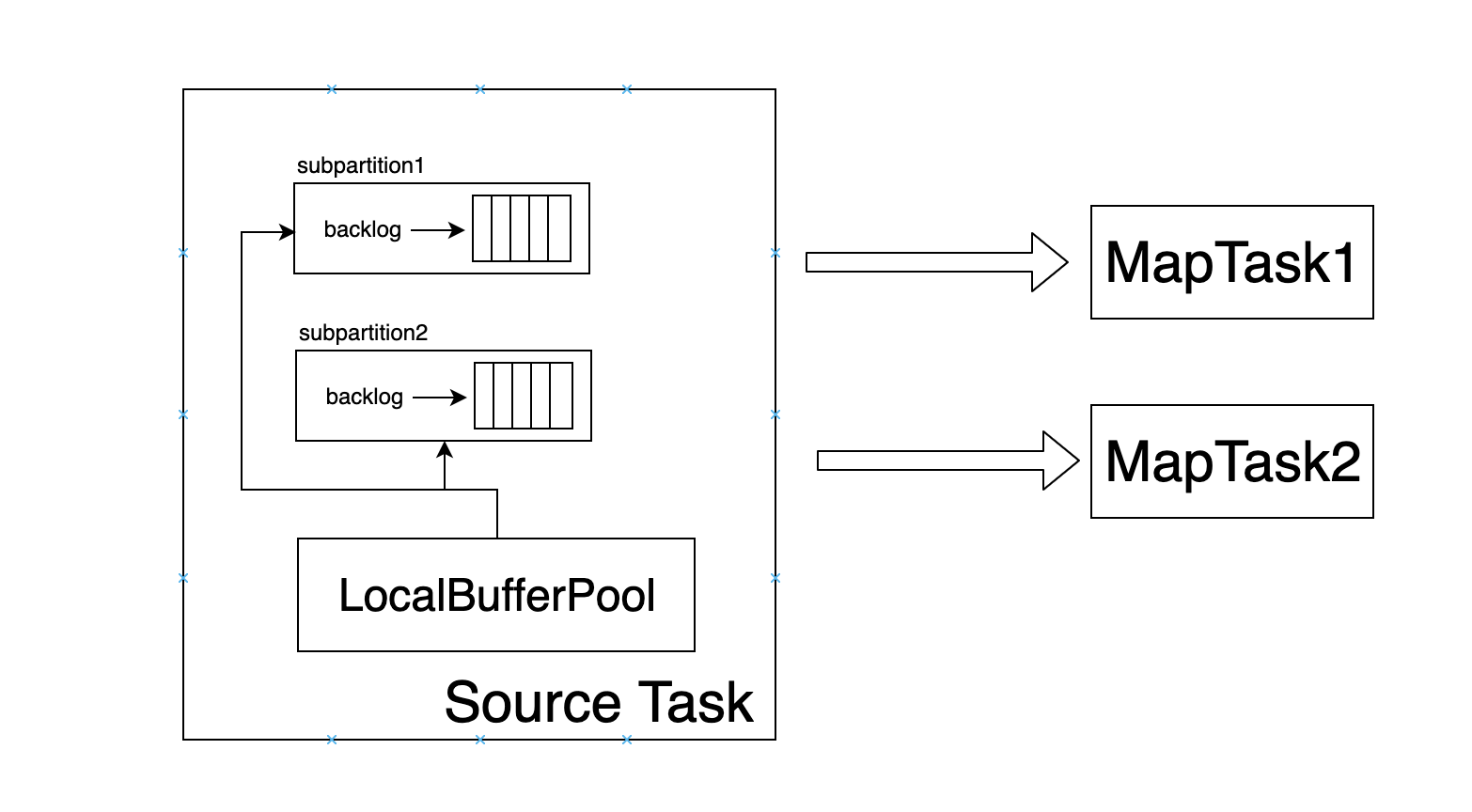
从图中可以看到,同一个 Task 的不同的 subpartition本身是共享一个 LocalBufferPool 的,并没有采取类似 credit-based 机制,当有数据发送时,直接从 LocalBufferPool 获取MemorySegment封装当前的数据然后发送。那么此时,有没有可能发送慢的 subpartition 抢占了 LocalBufferPool的所有资源,而发送快的 subpartition 由于迟迟获取不到资源而阻塞呢?
答案显然肯定的,我在这里贴出我的 demo 代码,大家可以试一下。我在代码中强制让一个 task 的消费速率变慢,由于 MapTask 的消费速率小于了 SourceTask 的生产速率,而我们的数据均衡机制又是采用 Round-Robin 的方式,所以导致 LocalBufferPool 的所有资源都被应该发送到消费慢的 MapTask 的 subpartition 抢占,而应该发送到消费快的 MapTask 的 subpartition 获取不到资源而被阻塞。
@Test
def testRebalance(): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(2)
env.getConfig.setMaxParallelism(2)
val sourceStream = env.addSource(new SourceFunction[(Int, Int)] {
override def run(ctx: SourceContext[(Int, Int)]): Unit = {
while (true) {
0 until 10 foreach {
// keys '1' and '2' hash to different buckets
i => ctx.collect((1 + MathUtils.murmurHash(i) % 5, i))
}
}
}
override def cancel(): Unit = {}
})
sourceStream.rebalance.map(new RichMapFunction[(Int, Int), String] {
var block = false
override def open(parameters: Configuration): Unit = {
super.open(parameters)
if (getRuntimeContext.getIndexOfThisSubtask == 0) {
block = true
}
}
override def map(value: (Int, Int)): String = {
if (block) {
Thread.sleep(10000)
}
s"Subtask Index: ${getRuntimeContext.getIndexOfThisSubtask}"
}
}).print()
println(env.getExecutionPlan)
env.execute()
}
Optimization
在上述代码 demo 中,我采取的是 round-robin 的方式来均衡数据,也就是说,数据发送到哪个 subpartition 其实我并不关心,我只关心后续处理不要产生倾斜,反压等问题或现象。针对这种情况,优化方法当然是有的。Credit-Based 机制在发送端加入了一个 backlog 的概念,代表着有多少数据应该发送但是还没有发送,接收端会根据发送端 backlog 的大小来决定是否需要征用 Floating Buffer 的资源。同时,我们也可以利用 backlog 知道每个 subpartition 分别抢占了 LocalBufferPool 的多少资源。在这里,放一些关键代码:
新建一个特征 BacklogBasedSelector,让 RebalancePartitioner 实现这个特征。在 RecordWriter 中判断当前 channelSelector 是否具有 BacklogBasedSelector 的特征,如果具有,检查 targetChannel 是否存在堵塞现象。
if (targetPartition instanceof ResultPartition && channelSelector instanceof BacklogBasedSelector) {
targetChannel = ((ResultPartition) targetPartition).changIfBlockingChannel(targetChannel);
}
在 ResultPartition 中加入 changeIfBlockingChannel 函数。
public int changIfBlockingChannel(int subpartitionIndex) {
int bufferSize = bufferPool.getNumBuffers();
int backlogSize = subpartitions[subpartitionIndex].getBuffersInBacklog();
// 根据 bufferPool 的大小和 subpartition 的 backlog 大小来选择是否需要更换 targetChannel
}
当然,这个方式只能解决接收端的 RemoteInputChannel 地位平等的情况,如果是 keyBy 这样的操作,暂时就没有其他更好的办法了。