这是我去年在Flink Meetup北京站的一次分享。相关视频点击这里。主要分享了GrowingIO在实时模块上,技术栈从Spark到Flink的过程中所做的努力和收获的经验。
因为实际演讲中涉及到了一些基于GrowingIO的专有名词和相关的使用场景,在此删减了部分和技术无关的幻灯片。

上图介绍了GrowingIO的基本业务情况。GrowingIO采用无埋点技术,全量采集用户行为数据,并通过一系列大数据工具和可视化图表来帮助企业分析数据和迭代产品。无埋点技术带来的不仅是海量数据,对于数据工程师来说,更是数据处理方面关乎成本控制和效率提升的挑战。
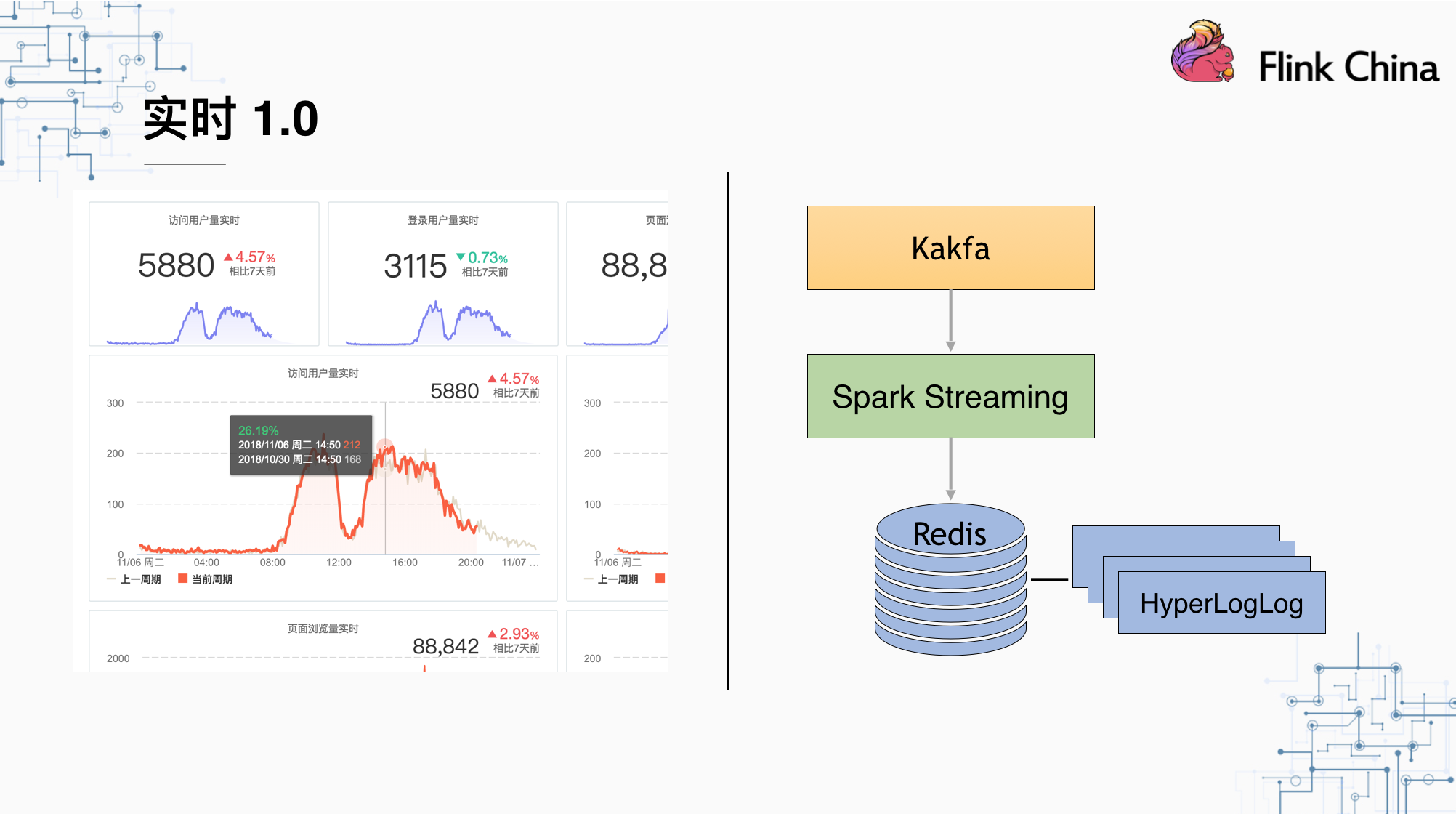
这是我们在实时1.0系统简化后的架构,使用Kafka作为数据源,Spark Streaming作为计算引擎,由于Redis拥有HyperLogLog存储结构,我们使用Redis作为人数和次数的存储。左边是GrowingIO平台中的可视化图表。
可以看出,1.0中可以提供的数据大多数只能用于简单的统计和监测,并不具有基本的分析功能,例如维度切分等。举一个场景:在某次活动中,期望实时观测活动效果,来即时调整各个渠道的投放量;或者通过期望实时效果监测来调整首页推荐商品的顺序,将人气较低的商品下架以提高商城整体的成单数。

一方面是上述的需求无法得到满足,另一方面是Spark Streaming对于真正实时的应用,还是有一些不太友好的地方。我们在使用Spark Streaming做实时应用时遇到了不少问题:
- 资源过多消耗。从右边的Streaming UI的截图可以看出,我们以10s作为一个批次,以达到一个接近实时的处理时延。但是每10s钟接收到的数据量是不一样的,导致了整个计算引擎在数据量相对较小时有部分时间闲置,而数据量相对较大时出现了处理时延。而实际上,闲置的资源应该去处理下一段时间接收到的数据,Flink采用了流式而不是微批的计算流,没有interval这个概念,也就不存在这个问题,可以很大程度上削平处理时延的高峰。
- 作业执行方式。Spark Streaming在每个interval之后会提交一个batch,这个batch的map和reduce过程是同步执行的,且每个batch都要进行任务的调度和执行计划的生成,这些都是没有必要的消耗
- 缺乏对处理的控制。Spark Streaming没有办法做到根据不同的客户需求来实现不同的实时性。不同的客户对于实时的定义可能是不一样的,采用Flink可以根据不同的Trigger来设定不同数据的输出频率,在加强定制化的同时也节省了资源。
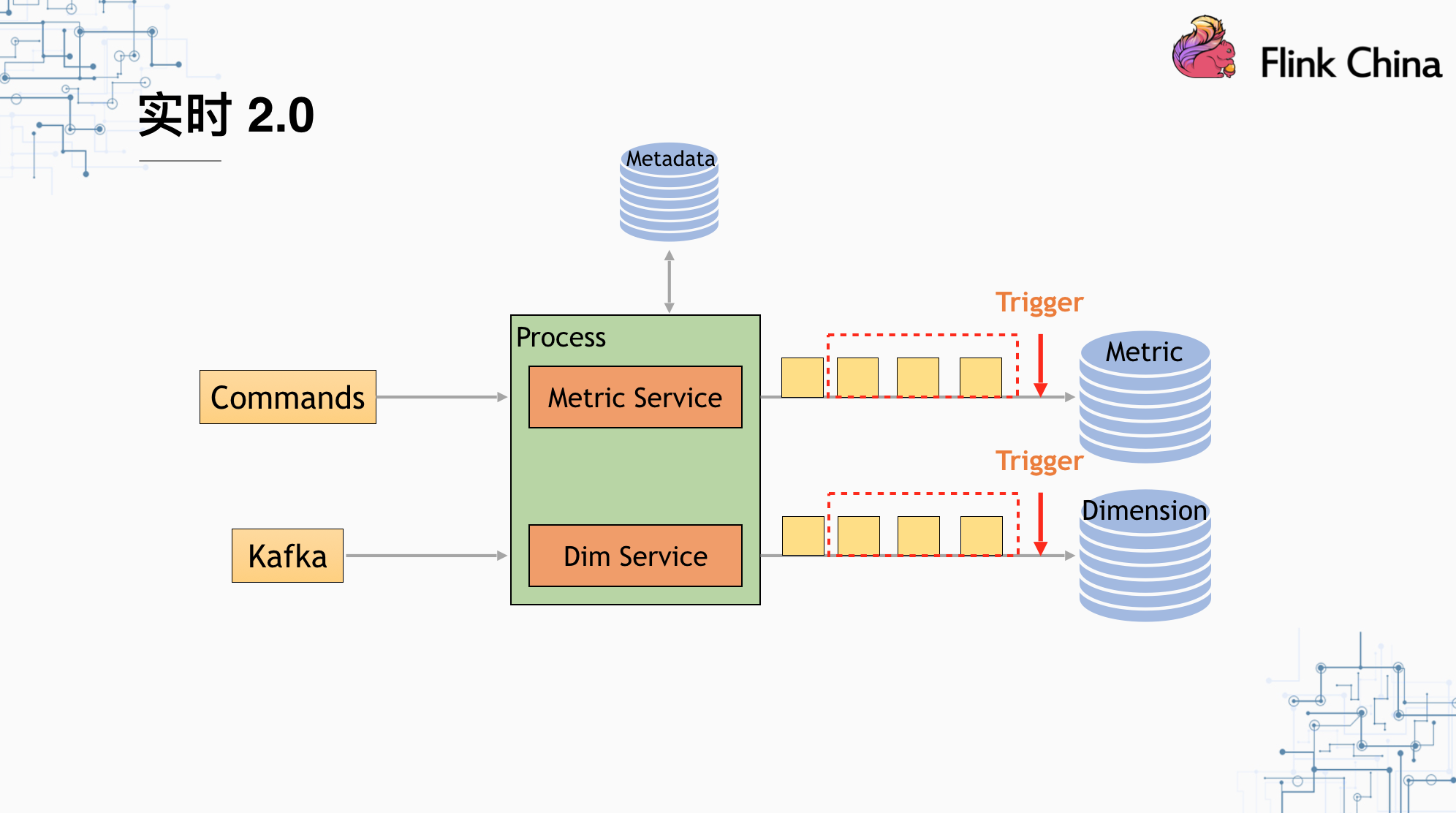
我们在实时2.0中采用Apache Flink作为计算引擎,数据源分为两类,一类是Kafka数据源,另一类是指令类数据源,主要作用是:
- 即时更新用户在图表上做的修改所对应的计算逻辑
- 控制Trigger的输出频率和指令
Process中是基于源数据的ETL操作,数据经过ETL之后,会经过我们的自定义Trigger和Window,然后输出到HBase的统计表中。
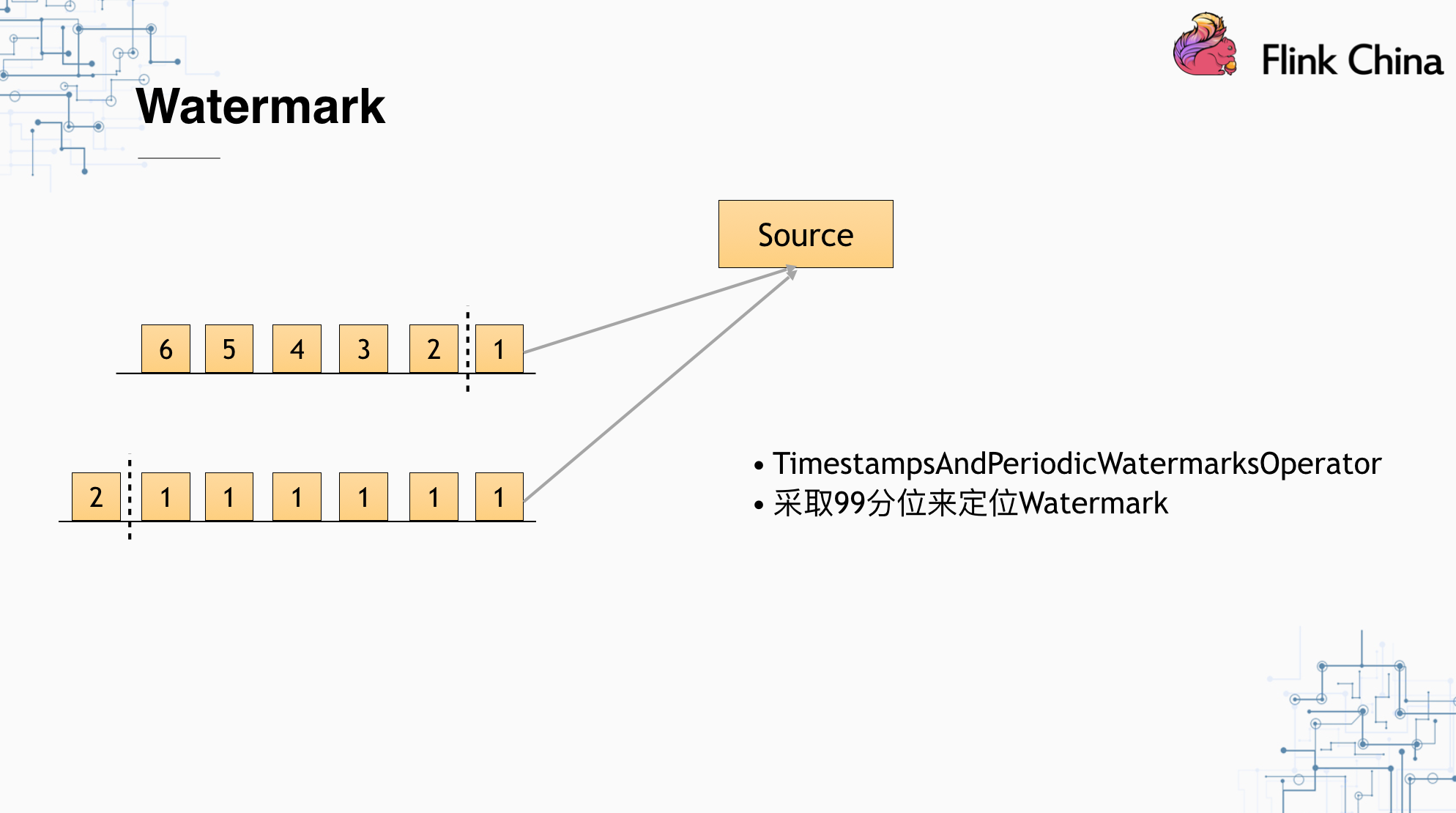
在Flink中使用Watermark,不可避免的是在判断Watermark时,会受到数据源倾斜的影响。假设我们的Kafka数据本身出现了倾斜,导致不同Operator接收到的数据的事件时间相差很远,这种情况下,我们采用收集到的事件时间从小到大排列中的99分位作为Watermark设置基准点。
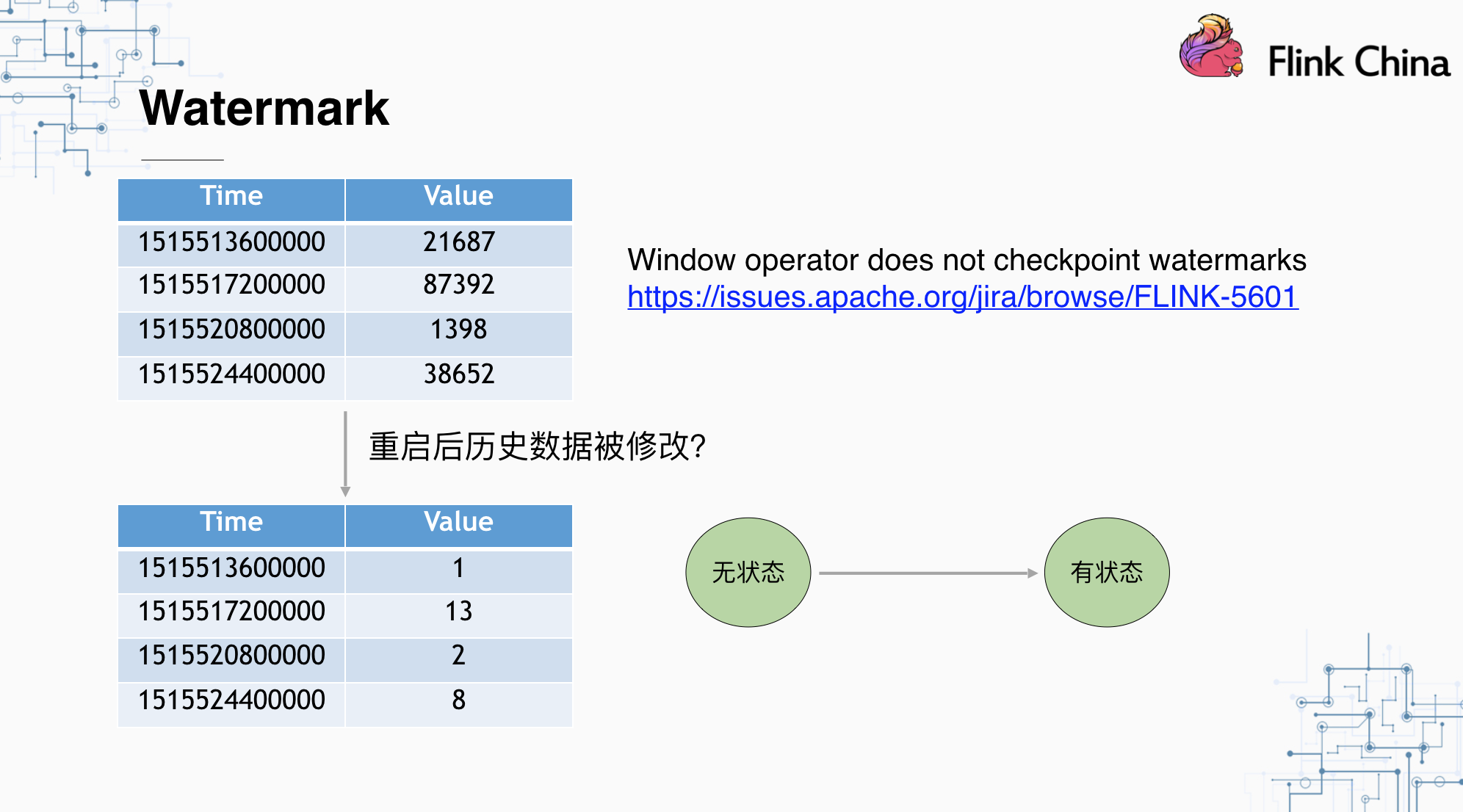
我们在实践中发现,Watermark并没有存储到Checkpoint中,那么当我们从状态点重启整个程序时,会出现迟到数据被错误接收的情况,也就是原本不应该被修改的历史数据被篡改。相关的问题已经在FLINK-5601体现,我们的解决方案是将WatermarkOperator从无状态变为有状态,利用UnionState在每次恢复时得到所有Watermark中的最小值,并在open初始化中将Watermark传递给之后的Operator。相关的解决方案已经提交给了社区。
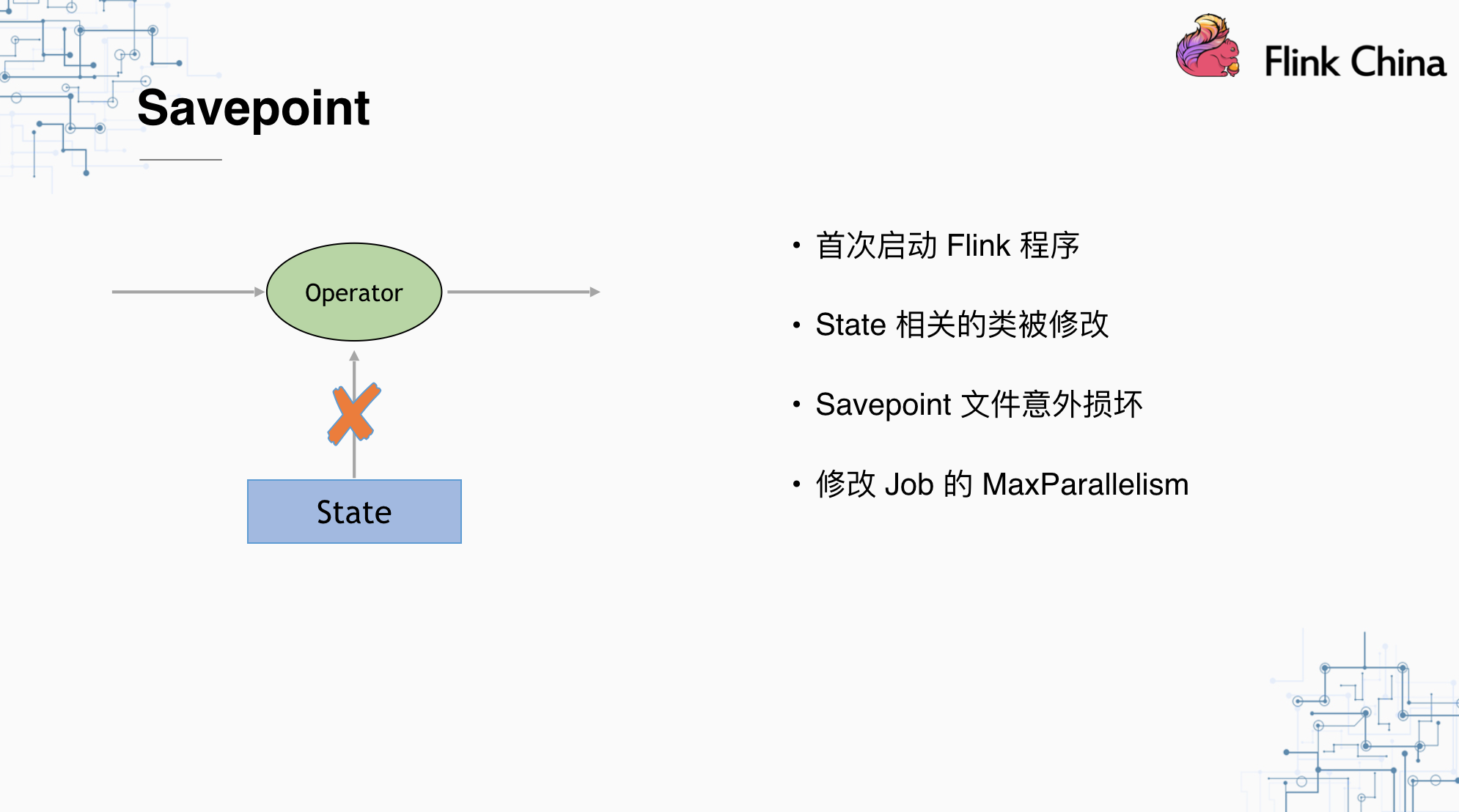
我们都知道Savepoint/Checkpoint本质上是状态的持久化,也就是将对象序列化到持久化存储的过程,所以如果我们想恢复程序,首先要保证的就是,我们恢复的程序中使用的对象,和之前序列化的对象必须是可以互相序列化/反序列化转换的。但有时候,Savepoint/Checkpoint不可避免的不可用,如:
- 首次启动Flink程序。由于程序第一次启动,没有持久化的状态点可以恢复。
- State相关类被修改。如Window中Aggregator的数据结构被改动。
- Savepoint文件意外损坏。如误删/磁盘故障等。
- 修改Job的MaxParallelism。这在Flink恢复时做了对应的校验。
针对以上情况,我们调研了三种解决方案:
使用ConnectedStream。
这种方案将我们要恢复的状态和实际的数据流结合起来,在程序启动初期,可以直接发送状态数据到Window中,从而达到Window State初始化的目的,对于其他Operator,采用类似的处理逻辑。这种缺点是,程序处理会变得非常不友好,大部分情况下存在一个没有数据的数据源,并且程序内部需要对聚合数据和明细实时数据做两种截然不同的处理。
使用bravo。
这是Flink社区内由开发者自主开发的一个程序,本质上是使用Flink批处理的API,读取Savepoint/Checkpoint的文件,采用和Flink源码中一样的反序列化逻辑,将状态反序列化。缺点是目前只支持RocksDBStateBackend,我个人曾经尝试过基于bravo去重写HeapStateBackend的序列化和反序列化的逻辑,但是由于其本身代码结构的一些原因,发现并不是那么容易实现。
-
Flink本身提供了一个不成熟的Feature叫QueryableState,利用这个功能,我们可以查询指定Operator中指定的状态。利用这个原理,我们在Read的基础上,写了一个Write的操作,在程序运行过程中,我们可以使用API实时向指定Operator注入状态。所谓有得必有失,由于State本身不是线程安全的,所以这样需要考虑State的线程共享问题,这样会带来一些性能上的损失。
未来展望
一般来说,数据的价值与其产生的时间成反比,越快拿到数据,那么数据的价值就越大。我们的行为数据分析,不会仅仅局限于多维分析和人群筛选,因为在越具体的场景中,策略的复杂性往往会越高。未来的话我们会往CEP上探索,因为Oracle目前已有了CEP SQL语法的相关规范和定义,calcite也在语法解析和逻辑计划层级上支持了大部分的SQL语法。而Flink目前对CEP的支持还没有达到我们期望的程度:
- 没有足够丰富的语法
- 不能同时匹配多个规则
- 无法动态修改规则
- 内存消耗过高
所以我们下一阶段计划基于Flink CEP,在能够解决上述问题的基础上,开发出适用于行为分析的CEP处理引擎,扩展出新的实时分析工具。