一本读了很长时间的书。
前言
首先声明下自己是数据相关的工程出身,大部分时间都在和分布式计算引擎打交道,对于业务知之甚少,尤其是推荐这种垂直类的业务和工程。所以整本书读下来收获还是非常非常大,我看知乎和豆瓣中很多对于本书的评价都说内容过于简单,真正有用处的是作者涉及到的引用文献,不过我觉得对于我当做课余读物来学习学习,还是足够了。
不管是业务知识还是技术知识,都对我有不少的帮助,先贴一下书的大纲:
(1) 好的推荐系统:介绍了不同场景下推荐系统的应用和评测方法
(2) 利用用户行为数据:从行为数据出发来实现推荐的算法
(3) 推荐系统冷启动问题:对于新手用户可以利用什么信息进行推荐
(4) 利用用户标签数据:熟悉的基于用户画像的推荐
(5) 利用上下文信息:利用时间、地点等信息
(6) 利用社交网络数据:基于社交关系的推荐方法
(7) 推荐系统实例:推荐系统的工程架构
(8) 评分预测问题:偏理论和学术,这部分暂时没有深度地看过
好的推荐系统
在如今信息过载的时代,推荐系统的任务是联系用户和信息。
换句话说,推荐系统是在庞大的信息库中,找到用户可能喜欢的信息,然后推送给用户。所以这里涉及到几个关键的问题:
- 如何找到用户可能的兴趣点?
- 如何涉及一个信息库可以存储如此多的信息,并且根据用户的兴趣点非常高效的搜索对应的信息?
- 如何推送给用户?以什么形式推送给用户?
如果工程化地思考上述 3 个问题,得到的就是
- 如何找特征?
- 存储结构如何设计?
- 产品形式?推荐的可解释性?
这些问题在后续的章节都有不同的解释,在这里我认为其最核心的部分就是找特征了,找特征需要非常强的工程思维和业务敏感度,就像作者项亮在很多知乎回答中提到,一个算法从业人员最重要的能力就是了解业务的能力。
好的推荐系统从以下几个方面考量:
- 准确率和召回率:推荐系统中常用的指标,不做解释。
- 流行度:可以使用物品次数对数的值,流行度越大,说明推荐的商品越接近热门商品。
- 覆盖率:推荐给用户的所有商品占总商品总数的比例,若是 100%,则说明所有商品都至少推荐给了一个用户。如果需要更加准确些,可以加上商品流行度倒数的因子。
利用用户行为数据
基于用户的协同过滤
主要包含两个步骤:
(1) 找到和目标用户兴趣相似的用户集合。
(2) 找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
这里的关键点就是计算两个用户的兴趣相似度。
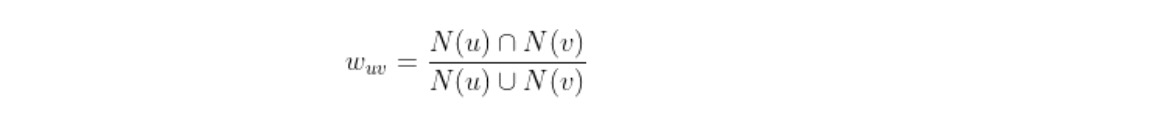
- N(u) 表示用户 u 购买的商品集合
但是这样会导致购买了热门商品的用户,本身并无共同兴趣但是被误认为有同一兴趣,所以我们需要在这里将商品的流行度加入到公式中来。也就是说,越是流行的物品,我们需要降低这一物品在计算相似度时的权重,可以使用购买 x 物品的人数来表示 x 物品的流行度,并使用流行度的倒数作为权重因子。因为流行度满足长尾分布,我们使用对数让数据变得更加均匀。
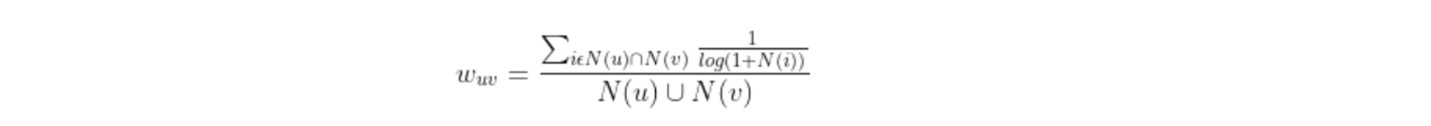
基于物品的协同过滤
主要包含两个步骤:
(1) 计算物品的相似度。
(2) 基于该用户的历史行为,推荐该用户没有听说过的物品。
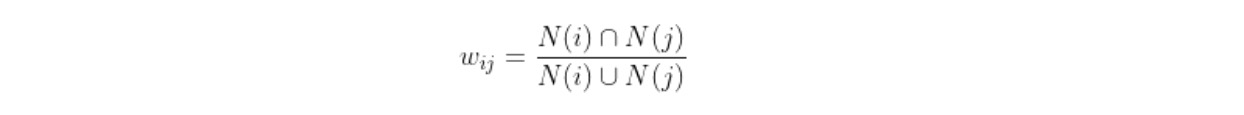
- N(i) 表示购买 i 商品的用户集合
同样,对于活跃的用户,我们需要降低异常活跃用户带来的权重,可以以用户 u 购买的商品来表示用户 u 的活跃度。
基于图的模型
用户 u 购买商品 i 的行为,可以以 (u, i) 二元组表示,从而形成一个无向图,这样,用户和物品,用户和用户,物品和物品之间的关系就联系了起来。
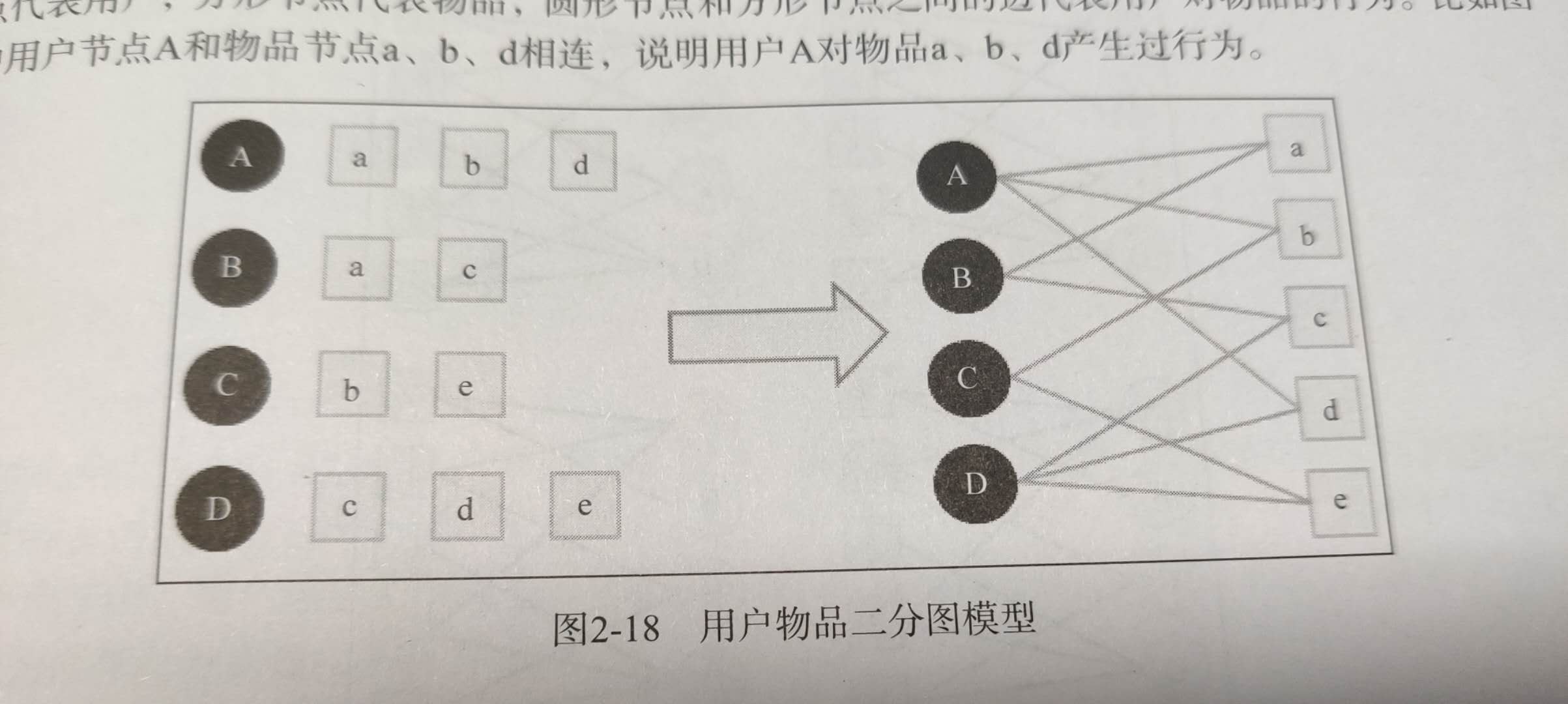
如图所示,若需要给用户 A 进行物品推荐,即可以用户 A 为节点,以 x 的概率随机游走,那么离用户 A 越远的物品被访问的概率就越小,通过多次实验迭代可以得出一个相对准确的访问概率,然后通过排序推荐给用户 A。
- 如果转换为矩阵求解则可以提供更加实时的计算结果。
推荐系统冷启动问题
这个章节的内容比较偏向业务,冷启动分为以下三类:
- 用户冷启动,新注册的用户。用户冷启动下可以利用用户注册的信息,或者像当下大部分 App 一样进入前先选择一系列的标签兴趣,然后推荐对应标签下热门的物品。
- 物品冷启动,新出现的物品如何推给用户。物品冷启动下可以将新物品随机地推给一些用户,相当于先把这些新物品”拿出来遛遛”,积累到一定量的数据之后便可以对其打上标签和属性。当然,目前的文章、视频等内容类产品,一般都有人工审核进行标注,这也可以成为推荐参考的属性。
- 系统冷启动,新网站,新产品,其实这就有些类似用户和物品都是新的,是上面两个冷启动的综合。
利用用户标签数据
这里主要讨论的是 UGC 标签,就像在 stackoverflow 上提问最后要加若干个 Tag 一样,让用户主动把内容的标签给打上,方便后续进行推荐。截止到这里,前面已经讲了两种主流的推荐方式:
- 根据用户的历史行为找到相似的物品进行推荐
- 找到用户相似兴趣的用户,推荐类似用户喜欢的物品
这里标签数据相当于是物品的特征,所以这种推荐方式是根据用户历史行为中喜欢的物品的特征,来推荐其他的物品。这里涉及到两个问题:
- 用户为什么要打标签?
- 用户打什么样的标签?
为什么要打标签
打标签的目的是给内容一些特征,而这些特征当然可以通过 NLP、图像分析等技术得到,但是这些技术得到的特征,未必是用户真正生产内容时所想的特征,比如照片里的一朵花,在不同的节日就会有不同的含义,用户所打的标签肯定也是不同的。
当这些内容具有一定特征之后,我们就可以将内容根据特征组织起来,或者进行分类,来更好的推荐给用户。
用户打什么样的标签
用户打什么样的标签,这里不是说用户随便写个标签就完了,这样标签只会越来越多,越来越杂,在这里可能需要借助 NLP 的一些算法处理同义词、停止词等。
当我们拿到物品的标签后,就可以得到用户 u 对物品 i 的兴趣公式如下:
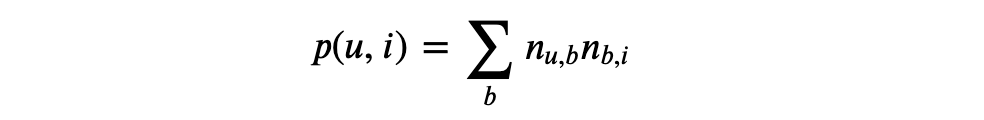
n(u,b) 表示用户 u 打标签 b 的次数,n(b,i) 表示物品 i 被打标签 b 的次数。当然,这里可以对热门物品进行优化,方法和上面一样。继续优化这个公式,做归一化:
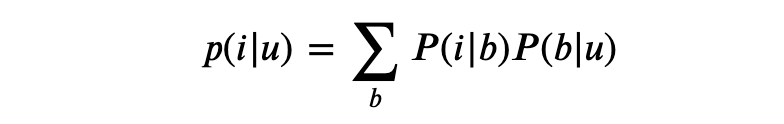
用户 u 对物品 i 喜欢的概率 = 物品 i 被打标签 b 的概率 * 用户 u 打标签 b 的概率
利用社交网络数据
社交网络定义了用户之间的联系,分为兴趣图谱和社会图谱两类,但看现在的产品,最终发展趋势其实都是有所混合的,不存在完全地偏向一种。利用社交网络可以帮助我们挖掘人和人之间的关系,直观一些讲,就是关系越密切的人,喜好可能越相似。
社交网络中用户之间的关系可以用”点”和”边”来表示,其中边分为单向边和双向边,我们可以使用 out(u) 来表示 u 的好友(关注的人),用户 u 对物品 i 的兴趣可以表示为:
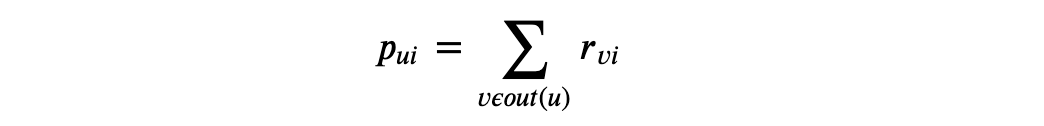
即找出有多少好友也对物品 i 有兴趣,这里如果要考虑好友之间的熟悉程度,可以加上对应的权重,而好友的之间的熟悉程度可以利用共同好友的比例来表示:
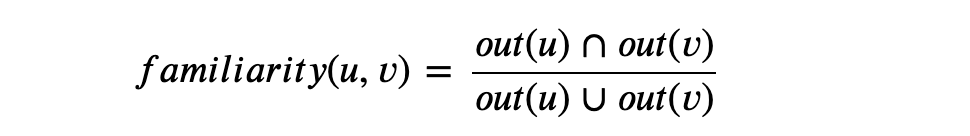
推荐系统实例
上面讲了这么多算法,实际应用场景中肯定不止一种,那么如何把他们融合在一起?之前提到的 3 种算法可以用下图表示:
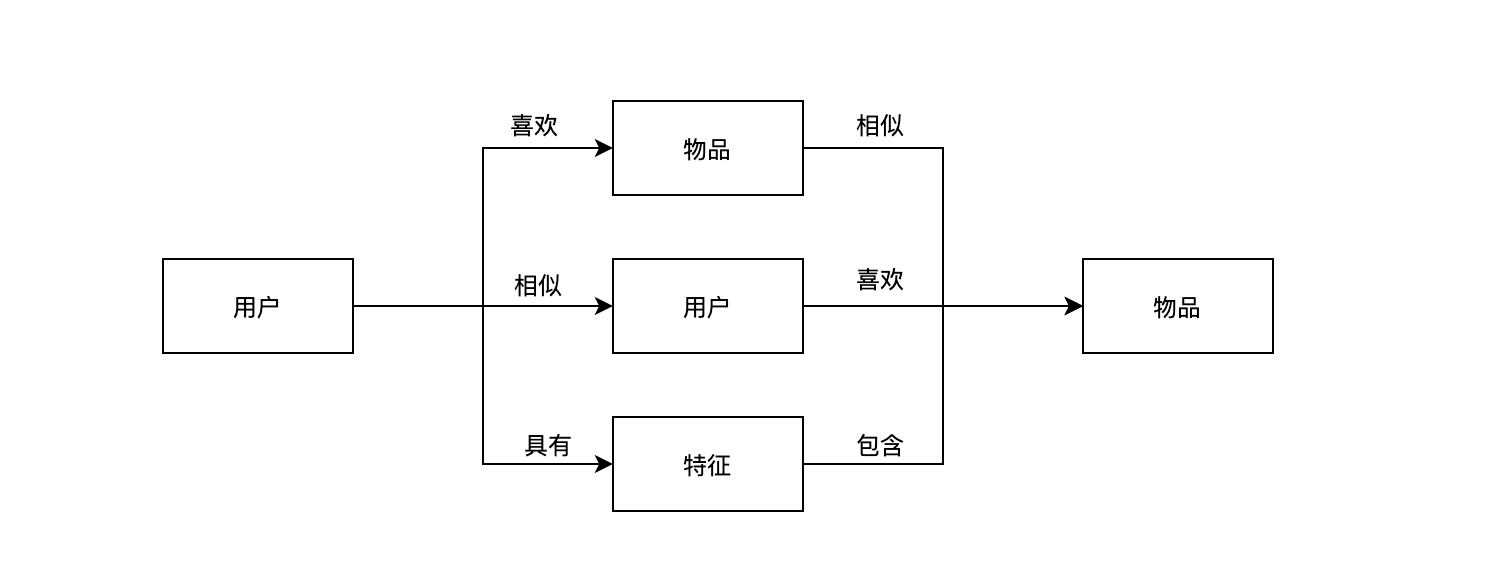
基于这个抽象,可以设计一种基于特征的架构。当用户到来后,推荐系统为用户生成多个特征,针对每个特征找到相关的物品,然后生成用户的推荐列表。因此,推荐系统的核心任务被拆解成两个部分,
- 如何为用户生成特征
- 如何根据特征找物品
我们将每一种特征的处理抽象成推荐引擎,做成插拔式的架构,通过所有推荐引擎的返回结果进行过滤、排序,最后生成推荐结果。
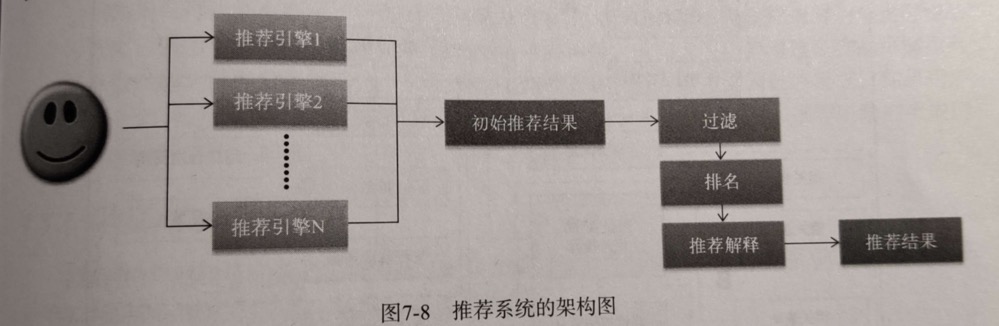
每个具体推荐引擎的架构:
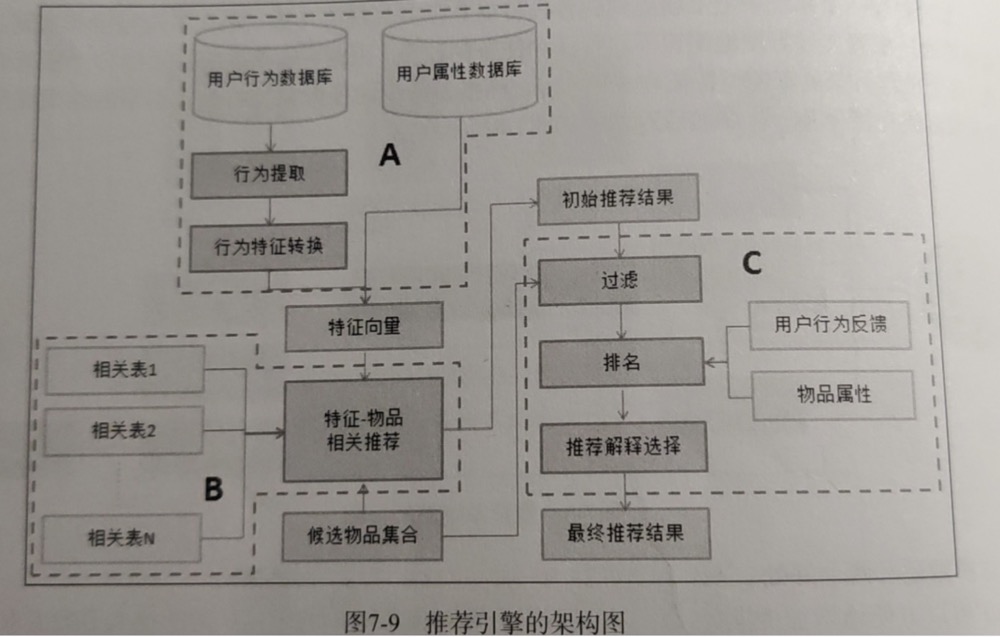
看到这里其实就已经比较清晰了,需要特别考虑下面几个点:
- 用户行为种类带来的权重,比如购买的权重应较大,浏览的权重应该较小
- 时间的权重,一般近期行为的权重比较重要
- 行为次数
- 热门程度
总结
总之呢,记住这张图。