一些平时不常接触但是很重要的基础知识。
JVM
多线程
ThreadPoolExecutor 的实现,几个关键点:
- 用 HashSet
来放置 Worker,这样提交新任务的时候可以扩容。 - 使用 java.util.concurrent.BlockingQueue 来存储任务。
- 在 Worker 中从 BlockingQueue 中无线循环拉去任务。
- BlockingQueue 有一个 size limit,会有 DiscardPolicy。
- 用 HashSet
ReentrantLock: 可重入且独占式的锁。有些类似 synchronized 但是有更多的功能。比如可以 tryLock(timeout) 这样,还可以检测锁是不是属于当前线程。可以给当前线程的 lock / unlock 计数。它的内部有公平锁和非公平锁两种,公平锁就是获取锁之前在等待队列中找有没有等待时间更长的线程,如果有就不分配。非公平锁就是直接抢占,不判断等待队列。正常情况下 tryLock(timeout) 会将线程放入等待队列中。
CyclicBarrier: 可以被多个线程使用的 barrier。构造方法有下面这两个,第 2 个构造方法的 Runnable 是所有线程释放锁之后触发的。 CyclicBarrier 的主要场景可以用来多线程计算数据,最后合并计算结果的场景。
public CyclicBarrier(int parties)
public CyclicBarrier(int parties, Runnable barrierAction)
CountDownLatch: 有点像火箭发射的倒计时。比如有10个线程要做准备工作,那么 CountDownLatch 从 9 到 0 之后,主程序才会继续运行。
HashMap / HashTable / ConcurrentHashMap: HashTable 线程安全,使用时锁住全表。 HashMap 数组链表,线程不安全。ConcurrentHashMap 线程安全,采取的是分段的数组+链表,把 Map 分为若干个 Segment,以 Segment 的粒度来加锁,value 使用 volatile,不用加锁。
- volatile
- mmap
- wait / notify: 需要在同步状态 synchronized 中使用。
- CAS(Compare And Swap): 基于乐观锁机制。
LOCK
- Fat Lock: 多线程访问资源,资源被竞争,性能消耗最大。
- Thin Lock: 多线程访问资源,但是不存在同时访问的情况,没有竞争。
- Recursive Lock: 资源被同一线程多次访问。
- Bias Lock: 只有一个线程会对资源进行访问。
JVM 内存模型
- 堆:堆是java虚拟机管理内存最大的一块内存区域,因为堆存放的对象是线程共享的,所以多线程的时候也需要同步机制。
- 方法区:类信息,常量。
- 栈:线程私有。存储局部变量表,操作栈,动态链接,方法出口等信息。每一个方法被调用的过程就对应一个栈帧在虚拟机栈中从入栈到出栈的过程。
- 程序计数器:线程独享,记录线程运行的位置。
- 本地方法栈:native层使用。
GC
GC基础:
stw 时,所有线程需要进入 safepoint。但是要保证 safepoint 前所有的线程对某些对象的操作保持一致,这个很困难。有时候 GC 导致的 stw 很短,但是进入 safepoint 的时间会很长。具体的详细信息可以加入相关的 GC 参数来看。
- Mark Reachable Objects: GC 会定义一些对象作为 GC Roots,如静态对象等,然后根据 GC Roots 的引用,不断迭代标记相关的对象,被标记过的就是存活对象。在标记的过程中,会出现 stw,stw 的时长和 Heap 中存活的对象有关系。
- Remove Unused Objects: 在做完标记之后,JVM 需要回收没有用到的对象。
- Sweep:清除之后,JVM 的内存空间里会出现断层,不利于之后的空间分配。
- Compact:清除后,整理剩余存活的对象,解决了 Sweep 的问题但是增加了 GC Pause 的时间。
- Copy:清除后,剩余存活的对象被 Copy 到另一块内存空间中。
GC 种类:
minor-gc-vs-major-gc-vs-full-gc
- Serial GC:新生代使用 mark-copy 老年代使用 mark-sweep-compact,单线程收集器,效率低,无法利用多核计算机的优势,过时算法,stw时间长。
- Parallel GC: 同上,但是多线程。
Concurrent Mark and Sweep(CMS):新生代使用 mark-copy,老年代使用 mark-sweep,主要是想降低 GC Pause 的时间,他本身分为 7 个阶段:
- Initial Mark: 开始标记老年代中 GC Roots,这点很重要,可能会扫描年轻代中的对象。(stw)。可能是本来就存在于老年代的 GC Roots,也有可能是从年轻代引用过来的对象。
- Concurrent Mark: 根据已经标记的老年代 Roots,开始标记老年代存活对象,不会 stw。因为没有做 stw,所以不是所有存活的对象都会被标记。
- Concurrent Preclean: 再做一次刚刚的事情,从 GC Roots 标记老年代存活对象,因为上一步没有做 stw,所以这一次把上一步引用发生变化的对象找出来,重新再标记一遍。
- Concurrent Abortable Preclean: 不知道在干什么。。。
- Final Remark: 会发生 stw。保证之前的 Preclean 已经跟上了 Application 运行的进度。
- Concurrent Sweep: 移除不需要的对象,不需要 stw。
- Concurrent Reset: 最后做 reset。
G1: Garbage First。将 Eden、Survivor、Tenured 三个区的内存打散,组成 Colelction 的单元结构,每次 GC 时以 Collection 的单元进行 GC,用户可以动态设置一些属性如 stw 最大时长,这样 G1 收集器会尽最大努力去做 GC。
引用
- Strong Reference:日常声明的对象就属于强引用,在没有对象对其进行引用时,通过 GC 消除。
- Weak Reference:除了 Weak Reference 之外,没有其他对象对其进行引用时,通过 GC 消除,并放在 weak reference 特有的 referenceQueue 中。
- Soft Reference:软引用,在内存空间不足时通过 GC 消除,可以用来做缓存使用。
分布式计算
- 数据倾斜问题
Apache Druid
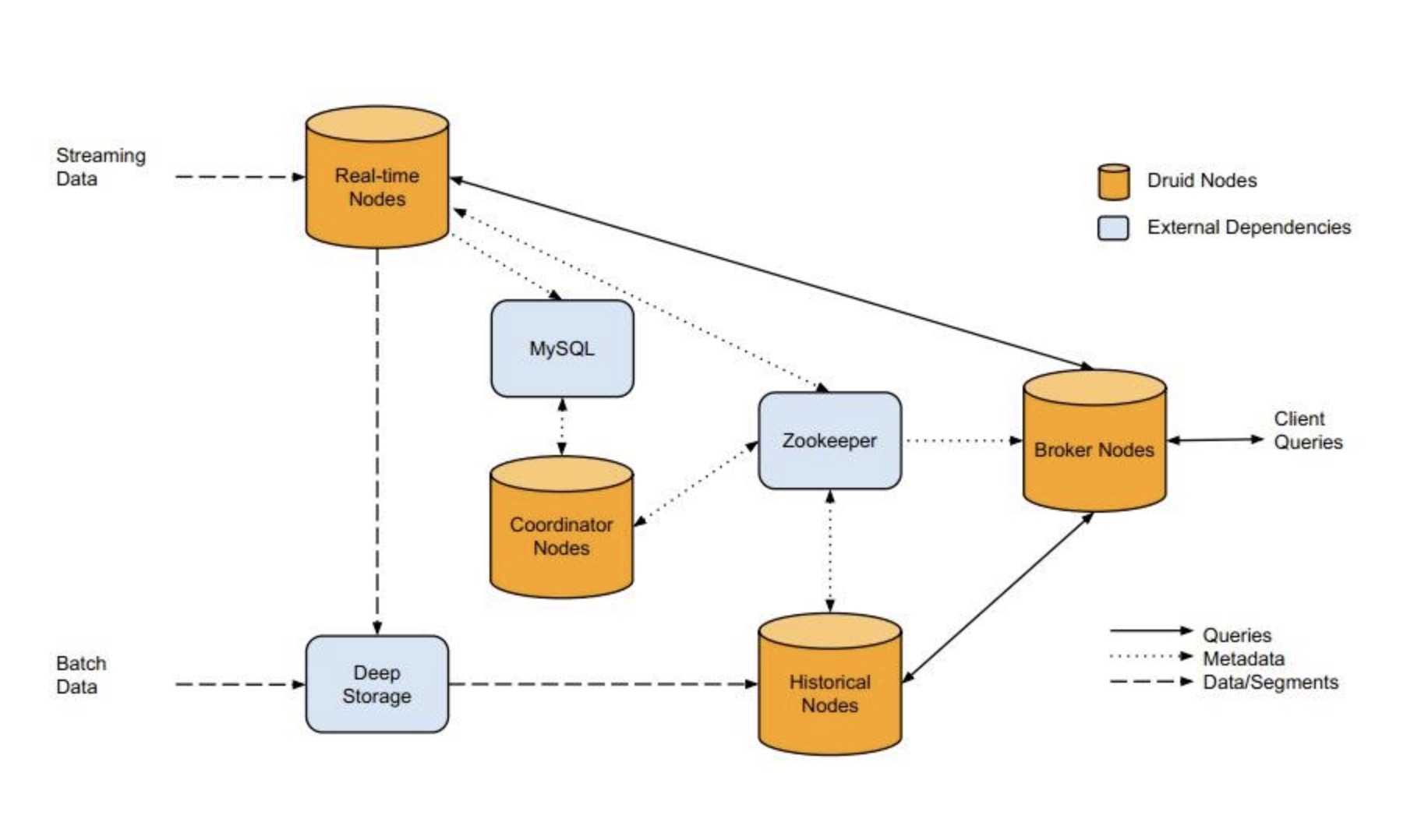
Impala
MPP 架构,通过 exchange 节点实现 shuffle。这种节点其实有点像是 spark external shuffle service ? 那么其实 MPP 和 map-reduce 模型本身并没有孰优孰劣,MPP 本身没有 shuffle 的一个操作,所以更加快速,更加适合简单的查询。
Presto
和 Impala 本身类似。
Apache Spark
- Spark Streaming backpressure: 基于 PID controller,根据速率线性稳步控制消费的条数。
Apache Flink
- Blink 优化: README.md
- FLIP-6: 增加 ResourceManager 和 Dispatcher,相当于从 YARN 等资源调度系统中获取资源之后,还可以对资源进行更细粒度的分配,可以更加灵活。可以灵活在不同的 job 中配置资源上的优先级。
- Flink 支持 incremental checkpoint,本身是使用了 RocksDB 的 LSM 特性,所谓的 incremental,指的是不用完整地复制前一个 checkpoint 产生的文件,只需要负责增量的部分数据落地即可,不是通过 compaction 来删除文件。
- Flink Exactly-Once vs At-Least-Once: 设置 CheckpointMode 为 Exactly-Once,CheckpointBarrierHandler 会选用 BarrierBuffer,此时 task 必须要接收到所有的 input 的 barrier 才能开始处理数据并发送 Barrier 给下游,在接收所有 barrier 之前,会将所有的数据缓存起来,放入 Buffer 中,如果缓存数据超过设置的大小,那么 checkpoint 宣告失败。 设置 CheckpointMode 为 At-Least-Once,CheckpointBarrierHandler 会选用 BarrierTracker,不会缓存数据,不需要保证 Barrier 的 Alignment。
- Flink Checkpoint: (1) operatorChain.prepareSnapshotPreBarrier (2) operatorChain.broadcastCheckpointBarrier (3) checkpoint
- Checkpoint 有 synchronous 和 asynchronous 两种模式,在 HeapStateBackend 中,这两种模式不太一样。但这两种模式都是会创建一个 CopyOnWriteStatTable,相当于要复制 一遍 StatTable,只不过 sync 模式是复制了一个 snapshot 之后,直接基于 snapshot 去持久化状态,而 async 模式,是将 FutureTask 传递下去,放到后面一起执行。
- Flink 网络栈传输的流程。
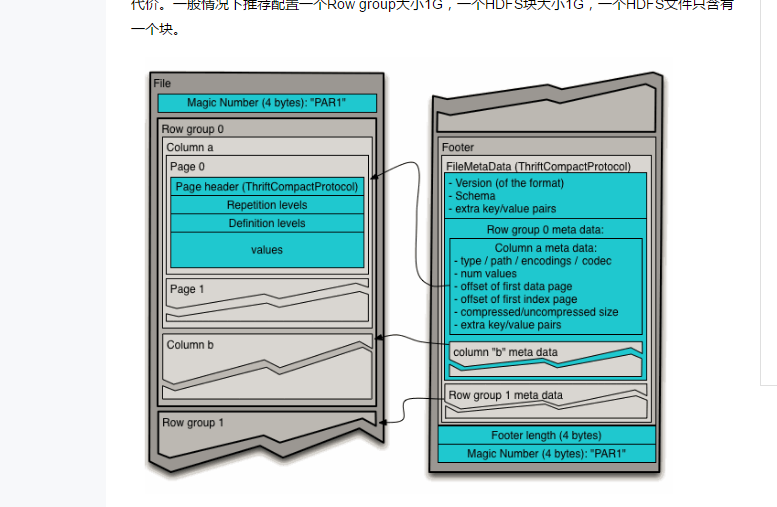
文件格式
Parquet: 自身是基于 Dremel 来实现的,支持结构化数据。如下:
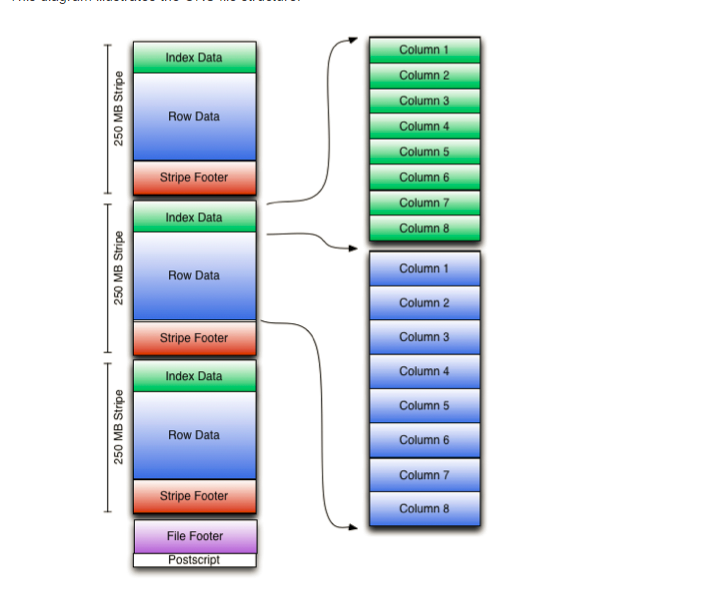
Orc: 采取的是行存+列存的方式,基本的存储单元是行,但是每个文件里分成了多个 strip,每个 strip 里有每列的一些元数据,可以加速过滤。如下
- RCFile: 有些类似 Parquet,但是不能像 Parquet 一样支持结构化的数据。