自己关于 Apache Hudi 的一些简单的了解。
背景
Hudi 是 Uber 主导开发的开源数据湖框架。所以大部分的出发点都来源于 Uber 自身场景,比如司机数据和乘客数据通过订单 Id 来做 Join 等。在 Hudi 过去的使用场景里,和大部分公司的架构类似,采用批式和流式共存的 Lambda 架构,我们先从 延迟,数据完整度还有成本 三个方面来对比一下批式和流式计算模型的区别。
批式模型
批式模型就是使用 MapReduce、Hive、Spark 等典型的批计算引擎,以小时任务或者天任务的形式来做数据计算。
- 延迟:小时级延迟或者天级别延迟。这里的延迟不单单指的是定时任务的时间,在数据架构里,这里的延迟时间通常是定时任务间隔时间 + 一系列依赖任务的计算时间 + 数据平台最终可以展示结果的时间。数据量大、逻辑复杂的情况下,小时任务计算的数据通常真正延迟的时间是 2-3 小时。
- 数据完整度:数据较完整。以处理时间为例,小时级别的任务,通常计算的原始数据已经包含了小时内的所有数据,所以得到的数据相对较完整。但如果业务需求是事件时间,这里涉及到终端的一些延迟上报机制,在这里,批式计算任务就很难派上用场。
- 成本:成本很低。只有在做任务计算时,才会占用资源,如果不做任务计算,可以将这部分批式计算资源出让给在线业务使用。但从另一个角度来说成本是挺高的,比如原始数据做了一些增删改查,数据晚到的情况,那么批式任务是要全量重新计算。
流式模型
流式模型,典型的就是使用 Flink 来进行实时的数据计算。
- 延迟:很短,甚至是实时。
- 数据完整度:较差。因为流式引擎不会等到所有数据到齐之后再开始计算,所以有一个 watermark 的概念,当数据的时间小于 watermark 时,就会被丢弃,这样是无法对数据完整度有一个绝对的报障。在互联网场景中,流式模型主要用于活动时的数据大盘展示,对数据的完整度要求并不算很高。在大部分场景中,用户需要开发两个程序,一是流式数据生产流式结果,二是批式计算任务,用于次日修复实时结果。
- 成本:很高。因为流式任务是常驻的,并且对于多流 Join 的场景,通常要借助内存或者数据库来做 state 的存储,不管是序列化开销,还是和外部组件交互产生的额外 IO,在大数据量下都是不容忽视的。
增量模型
针对批式和流式的优缺点,Uber 提出了增量模型,相对批式来讲,更加实时,相对流式而言,更加经济。
增量模型,简单来讲,是以 mini batch 的形式来跑准实时任务。Hudi 在增量模型中支持了两个最重要的特性,
- Upsert:这个主要是解决批式模型中,数据不能插入、更新的问题,有了这个特性,我们可以往 Hive 中写入增量数据,而不是每次进行完全的覆盖。(Hudi 自身维护了 key->file 的映射,所以当 upsert 时很容易找到 key 对应的文件)
- Incremental Query:增量查询,减少计算的原始数据量。以 Uber 中司机和乘客的数据流 Join 为例,每次抓取两条数据流中的增量数据进行批式的 Join 即可,相比流式数据而言,成本要降低几个数量级。
在增量模型中,Hudi 提供了两种 Table,分别为 Copy-On-Write 和 Merge-On-Read 两种。
Copy-On-Write Table
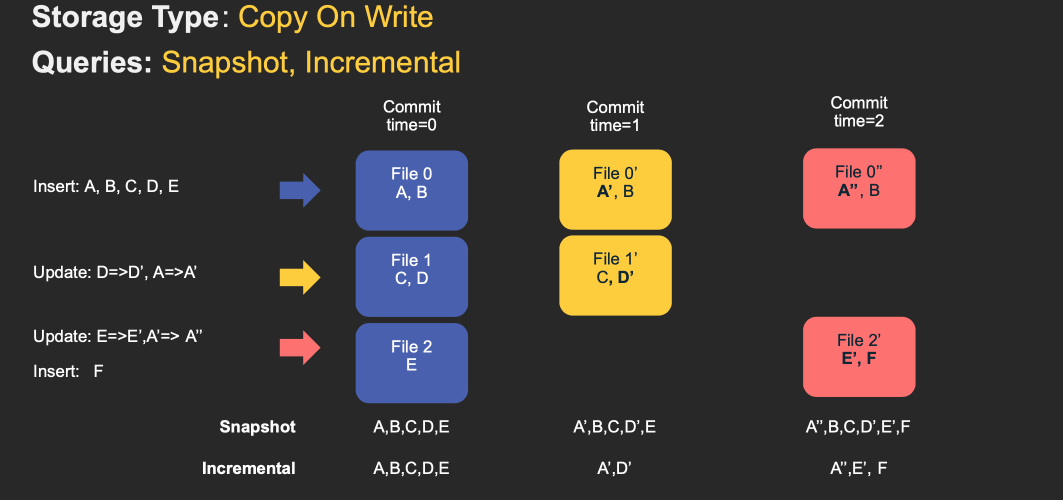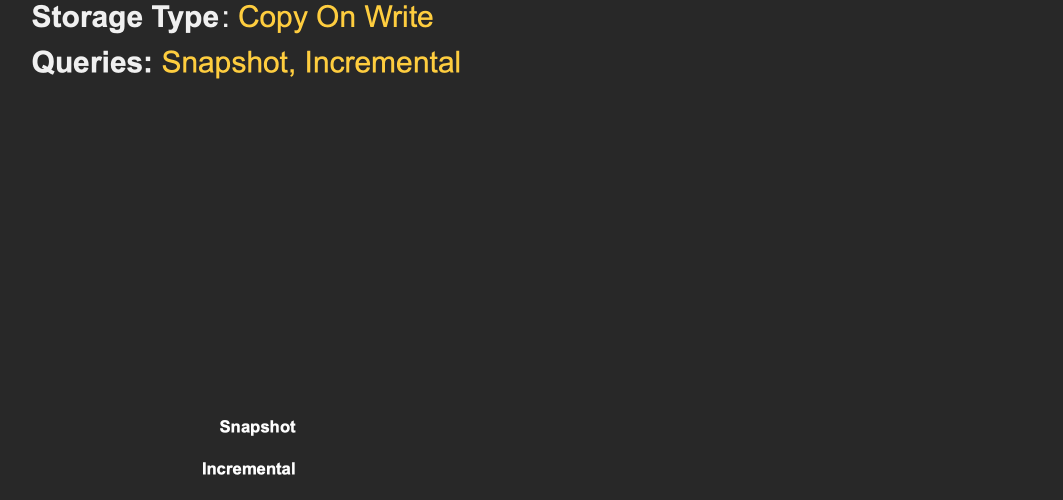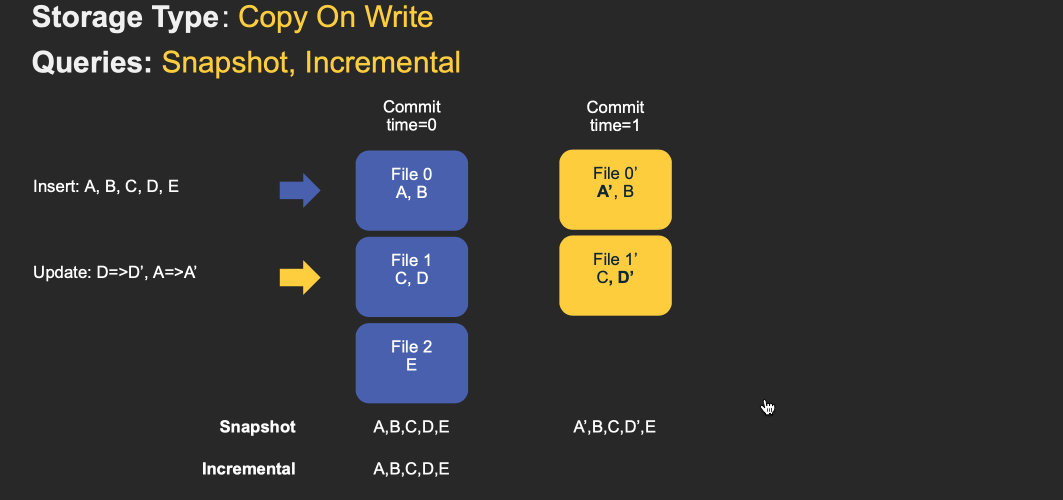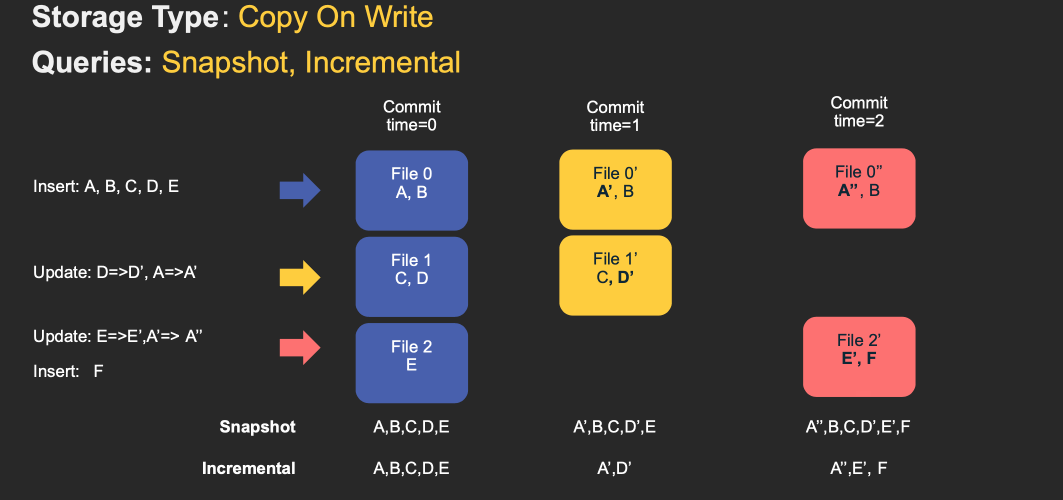
对于 Copy-On-Write Table,用户的 update 会重写数据所在的文件,所以是一个写放大很高,但是读放大为 0,适合写少读多的场景。对于这种 Table,提供了两种查询:
- Snapshot Query: 查询最近一次 snapshot 的数据,也就是最新的数据。
- Incrementabl Query:用户需要指定一个 commit time,然后 Hudi 会扫描文件中的记录,过滤出 commit_time > 用户指定的 commit time 的记录。
具体的流程见下图 gif:
Merge-On-Read Table
对于 Merge-On-Read Table,整体的结构有点像 LSM-Tree,用户的写入先写入到 delta data 中,这部分数据使用行存,这部分 delta data 可以手动 merge 到存量文件中,整理为 parquet 的列存结构。对于这类 Tabel,提供了三种查询:
- Snapshot Query: 查询最近一次 snapshot 的数据,也就是最新的数据。这里是一个行列数据混合的查询。
- Incrementabl Query:用户需要指定一个 commit time,然后 Hudi 会扫描文件中的记录,过滤出 commit_time > 用户指定的 commit time 的记录。这里是一个行列数据混合的查询。
- Read Optimized Query: 只查存量数据,不查增量数据,因为使用的都是列式文件格式,所以效率较高。
具体的流程见下图 gif:

想法
关于上述的内容,Hudi 自身提供了一个比较便捷的 Docker Demo,让用户可以很快地上手。
谈到数据湖框架,大家都会说出现在比较流行的三个开源软件,分别为 Delta Lake、Apache Hudi 和 Apache Iceberg。虽然经常把他们拿来一起比较,但是实际上每个框架的背景都是不一样的。
比如 Iceberg 的初衷是解决 Netflix 内部文件格式混乱的问题,Hive Table 中即可能是 csv,也可能是 parquet 文件格式,用户在做一些 metadata 的修改时,需要清楚的知道自己所操作 Table 的很多属性,针对这个痛点,Iceberg 提出了 everything can be a table 的概念,期望用 Iceberg Table 来统一所有的 Table。
而 Hudi 提出的则是批流两种计算模型的折中方案,Delta 我了解的不算太多,但是总体跟 Hudi 比较类似。目前 Apache Iceberg 也在积极地做 Row-Level Update,也就是类似 Hudi 的 upsert 功能。
虽然出发点不同,但是三种框架无一例外都是指向了 Hive 这个统治数仓数十年,但是数十年来变化并不大的框架,随着数十年来 Hadoop 生态的发展,Hadoop 生态支持的数据量、数据类型都有一个很大的提升,以 Hive 做数仓必然是比较简单,但是 Hive 本身对 Table 中的内容掌控度是比较小的。以仓储为例,Hive 相当于只是提供了一个仓库,但是没有利用仓库中的内容去做一些优化,大家只是把东西放到仓库里,但是仓库的东西一多,大家找东西就会比较乱,而新兴的数据湖框架,既提供了一个仓库的功能,同时还给仓库配上了标签信息、监控工具、智能运输等功能,即使仓库装的很满,用户也可以轻松根据标签定位到具体的货架。